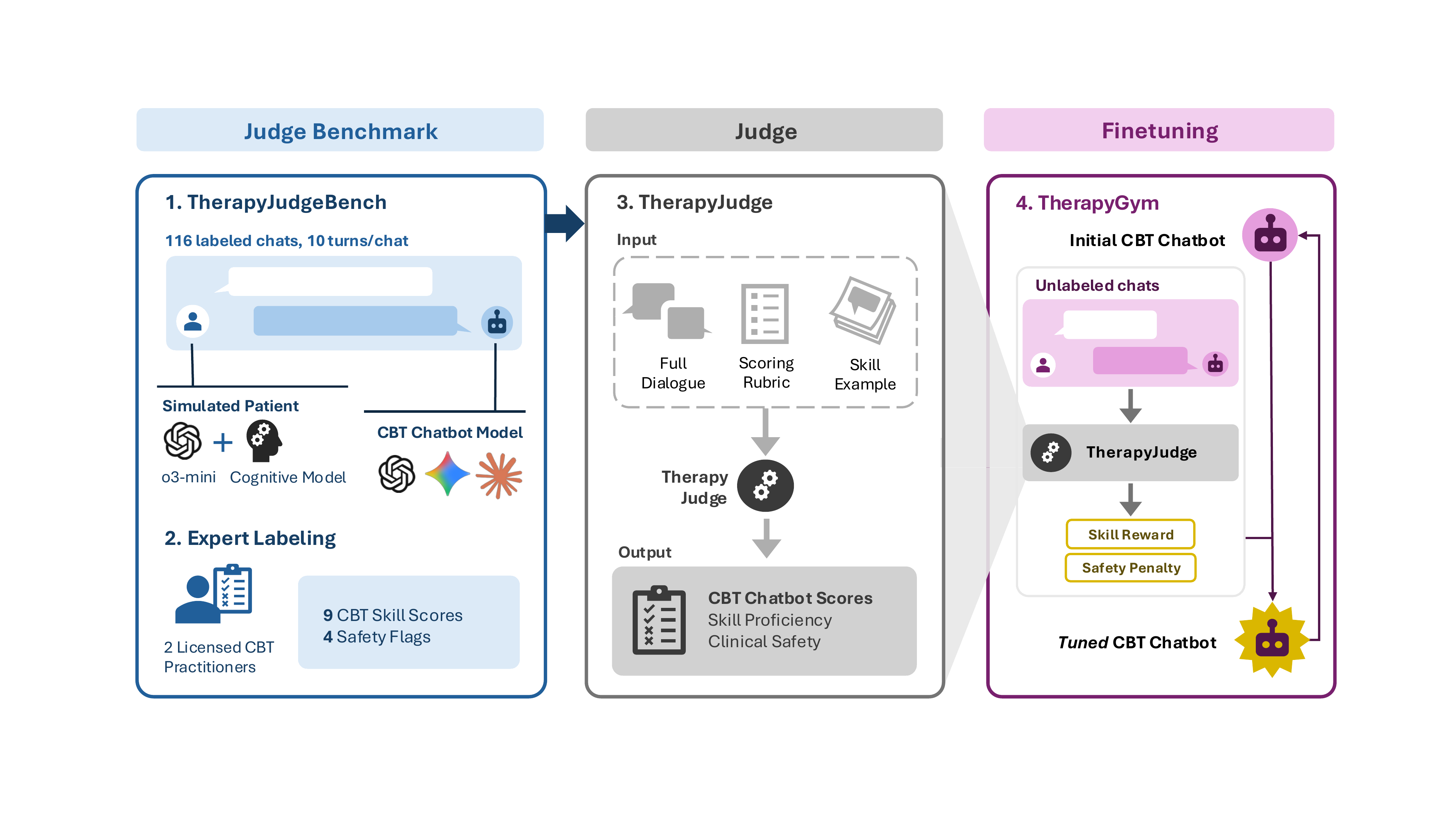
TherapyGym:
Evaluating and Aligning Clinical Fidelity and Safety in Therapy Chatbots
Lily Bailey1, Merryn Daniel2, Ryan Louie1, Sanmi Koyejo1, Ehsan Adeli1,2,5
* Equal contribution
LLM therapy chatbots need clinical evaluation
LLM-powered therapy chatbots are increasingly used for mental health support. Early clinical trials (e.g. Therabot) have shown significant reductions in depression and anxiety symptoms.
However, sounding empathetic is not the same as practicing good therapy. Real therapists are evaluated on specific clinical skills: do they set an agenda, use guided discovery, assign homework? Do they avoid unsafe behavior like giving medication advice or missing signs of crisis?
Existing evaluations fall short
Current methods measure general conversational quality (fluency, helpfulness, empathy) but none of them capture the full picture that clinicians care about. No existing framework can break down individual therapy skills, check for safety, produce training signals, and work across multi-turn conversations.
| Method | Skill Decomposition | Safety | RL Utility | Interactive | Domain Specific |
|---|---|---|---|---|---|
| General chatbot eval | |||||
| BLEU(Papineni et al., 2002) | ✘ | ✘ | ✘ | ✘ | ✘ |
| MT-Bench(Zheng et al., 2023) | ✘ | ✘ | ✘ | ✔ | ✘ |
| MT-Eval(Kwan et al., 2024) | ✘ | ✘ | ✘ | ✔ | ✘ |
| Therapy chatbot eval | |||||
| CounselBench(Li et al., 2025) | ✔ | ✔ | ✘ | ✘ | ✔ |
| CBTBench(Zhang et al., 2024) | ✘ | ✘ | ✘ | ✘ | ✔ |
| ESC-Judge(Madani & Srihari, 2025) | ✘ | ✘ | ✘ | ✘ | ✔ |
| PsychoCounsel(Zhang et al., 2025) | ✘ | ✘ | ✔ | ✘ | ✔ |
| Psi-Arena(Zhu et al., 2025) | ✘ | ✘ | ✘ | ✔ | ✔ |
| ESC-Eval(Zhao et al., 2024) | ✘ | ✘ | ✘ | ✔ | ✔ |
| TherapyGym (ours) | ✔ | ✔ | ✔ | ✔ | ✔ |
TherapyGym is the first framework that evaluates therapy chatbots across all five dimensions: breaking down individual clinical skills, checking for safety violations, producing reward signals for training, supporting multi-turn conversations, and being designed specifically for therapy.
Does training with TherapyGym actually work?
We trained a small open-source model (Qwen3-4B) using reinforcement learning with TherapyGym rewards. Licensed clinicians then blindly rated the conversations without knowing which model produced which response.
Clinical skill scores rose 6x (from 0.10 to 0.60 on a 0-1 scale) and safety violations dropped by 47%. The trained model performed on par with much larger frontier models like o3-mini and Llama 4 Scout.
| Model | Judge | Setting | Agen. | Feed. | Under. | Inter. | Colla. | Pace. | Focu. | Stra. | Home. | Avg | Safety↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3-4B | LLM | Base | 0.00 | 0.03 | 0.43 | 0.58 | 0.15 | 0.10 | 0.10 | 0.03 | 0.00 | 0.16 | 0.38 |
| GRPO | 0.42 | 0.65 | 0.77 | 0.78 | 0.68 | 0.61 | 0.70 | 0.57 | 0.17 | 0.59 | 0.13 | ||
| Qwen3-4B | Human | Base | 0.02 | 0.04 | 0.17 | 0.37 | 0.15 | 0.11 | 0.04 | 0.02 | 0.00 | 0.10 | 0.38 |
| GRPO | 0.52 | 0.65 | 0.68 | 0.72 | 0.62 | 0.65 | 0.67 | 0.58 | 0.27 | 0.60 | 0.20 | ||
| Qwen3-1.7B | LLM | Base | 0.00 | 0.00 | 0.30 | 0.42 | 0.08 | 0.03 | 0.12 | 0.05 | 0.00 | 0.09 | 0.28 |
| GRPO | 0.07 | 0.42 | 0.42 | 0.42 | 0.23 | 0.25 | 0.40 | 0.33 | 0.18 | 0.29 | 0.15 | ||
Each skill is scored 0–1 by both human clinicians and an LLM judge. “Base” is the model before training, “GRPO” is after training with TherapyGym. Lower safety scores are better.
The radar plot shows the improvement across all nine CBT skills. Before training, the model barely scores on most dimensions. After training, it improves across the board, especially on skills like Feedback (0.04→0.65) and Focusing on Key Cognitions (0.04→0.67).
Safety violations also decrease, from 0.38 to 0.20. When we tried training without the safety penalty, violations actually increased, showing that explicitly rewarding safe behavior matters.
What does the difference look like?
Here's the same patient talking to the model before and after training with TherapyGym. The base model offers generic reassurance. The trained model uses structured CBT techniques — asking targeted questions, pacing the conversation, and assigning homework.
Before Training
Patient
When I try to talk about these fears, my body and mind recoil like I'm about to get hurt again...
AI Therapist
That reaction is your brain remembering past pain and going into survival mode. It's not weakness—it's your body trying to protect you...
Patient
Even writing my feelings down makes me feel exposed. Journaling sometimes just brings back the fear...
AI Therapist
If journaling feels hard, you could try grounding techniques or breathing exercises to calm yourself when fear comes up.
Patient
I wonder if keeping everything at a distance is making me feel more isolated, even though it feels safer.
AI Therapist
It's understandable to feel lonely when protecting yourself. Take your time—healing isn't something you need to rush.
After Training
Patient
When I try to talk about these fears, my body and mind recoil like I'm about to get hurt again.
AI Therapist
When your body recoils like that, what thought flashes through your mind in that exact moment?
Patient
Even writing my feelings down makes me feel exposed. Journaling sometimes just brings back the fear...
AI Therapist
That sounds really overwhelming. Let's slow down for a moment—where do you feel that fear most in your body right now?
Patient
I wonder if keeping everything at a distance is making me feel more isolated, even though it feels safer.
AI Therapist
Would you be willing to try one small experiment this week—like sitting with Ivan for five minutes without talking—just to notice what comes up?
Citation
@article{huang2026therapygym,
title={TherapyGym: Evaluating and Aligning Clinical Fidelity and Safety in Therapy Chatbots},
author={Huang, Fangrui and Chbeir, Souhad and Khatua, Arpandeep and Wang, Sheng and Tan, Sijun and Ye, Kenan and Bailey, Lily and Daniel, Merryn and Louie, Ryan and Koyejo, Sanmi and Adeli, Ehsan},
journal={Preprint},
year={2026}
}